The Architecture Behind My 24/7 AI Operations Partner
The model is not the product. The workflow is the product. Here is a technical look at the production stack behind a physician-built AI operations partner: Docker, Traefik, model failover, rate limits, logs, HIPAA boundaries, and the failure modes I watch for every week.
Listen to this post
The Architecture Behind My 24/7 AI Operations Partner
In Part 1, I described what it looks like to run a 94-skill AI operations partner across clinical, coding, theological, and infrastructure workflows. I described what it does.
In this post, I want to go under the hood.
Because the magic is not the model.
The magic is the system.
That distinction matters for physician-developers. Most AI conversations begin and end with the model name. GPT. Claude. Gemini. Llama. Kimi. The model becomes the brand, the identity, and the argument.
But production AI is not a model. Production AI is a stack.
It is hardware, containers, reverse proxies, ports, environment variables, API keys, token limits, logs, storage, permissions, backups, cron jobs, failover models, monitoring, prompts, skills, and human review.
The model is only one organ in the body. If the rest of the body is poorly designed, even a brilliant model becomes unreliable.
That is the lesson I keep returning to as a physician-developer: clinical AI will not succeed because somebody plugged a language model into a hospital. It will succeed when clinicians and technologists build systems that respect the reality of clinical work.
My Hermes deployment is not a hospital-grade enterprise system. It is a physician-builder production stack. But that is exactly why it is instructive. It lives close to the ground. It reveals the problems that polished demos hide.
The Infrastructure Foundation
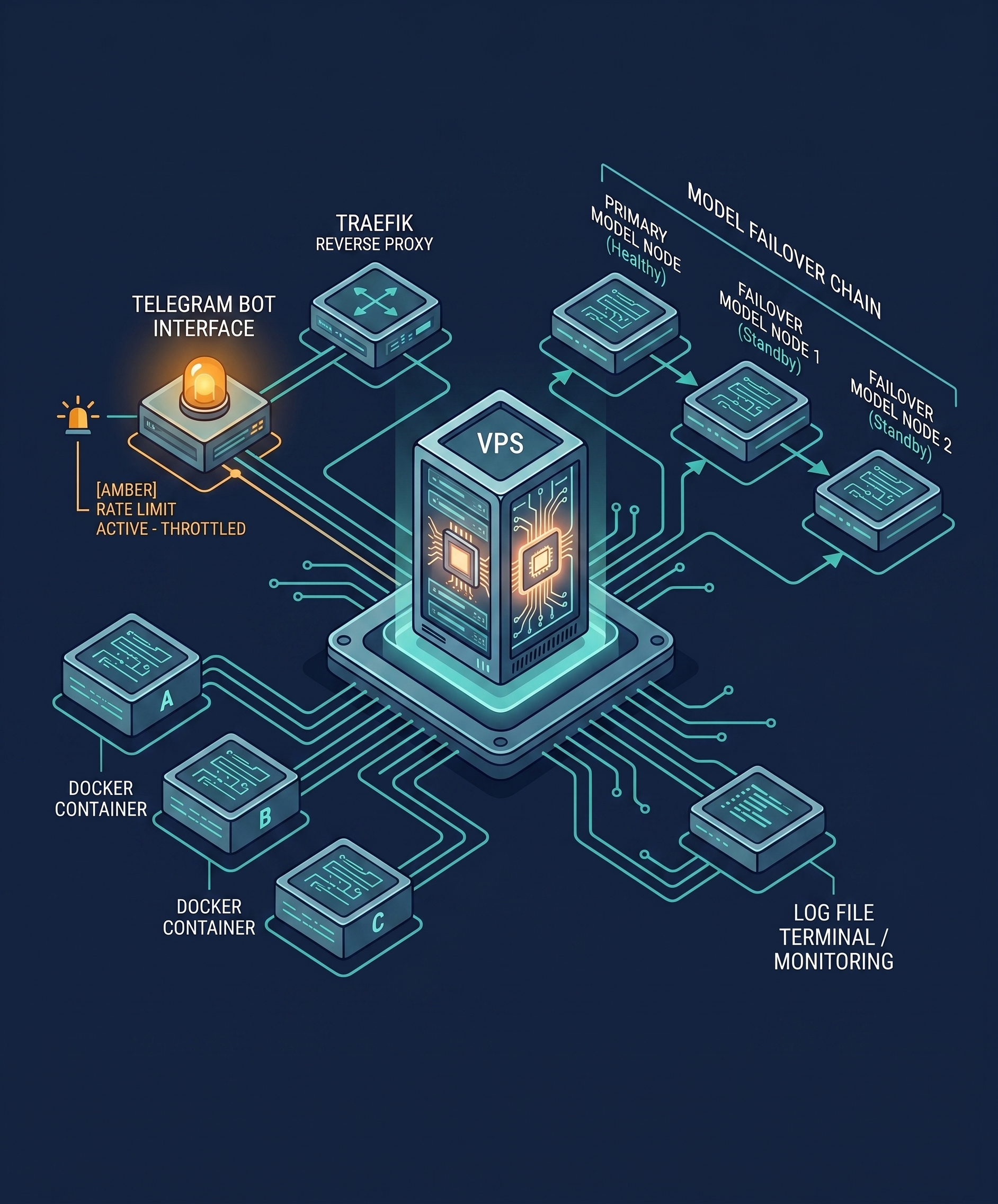
The system runs on a Hostinger VPS using Docker and Traefik.
The server gives me a stable place to run the Hermes stack continuously, instead of treating AI as something that only exists when I open a browser tab. That alone changes the psychology of the tool.
A browser chatbot is episodic. A server-based agent is persistent.
Persistence is the difference between “answer this question” and “support this workflow.”
The container architecture separates services by port and role:
- 4860 for external ttyd web terminal access
- 8642 for the internal API server
- 8787 for the internal web UI
- 9119 for the internal gateway
Each component has a specific job. The gateway routes agent behavior. The API server exposes internal functionality. The web UI provides an interface. The terminal gives operational access.
That modularity matters because AI systems fail in boring ways.
A port conflict. A container restart. A missing environment variable. A permissions issue. A rate limit. A log file that grows too large. A cron job that silently stops working.
These are not glamorous problems. They are production problems. And production problems are where healthcare AI will either mature or collapse.
The Root Access Problem
One of the uncomfortable realities in my build was running the gateway with root permissions, requiring HERMES_ALLOW_ROOT_GATEWAY=1.
That sentence should make every security-minded reader pause.
It made me pause too.
Running as root in production is not ideal. In a healthcare-adjacent workflow, it raises immediate questions about permissions, blast radius, and system boundaries. But this is where physician-builders encounter the tension between clean security theory and practical deployment reality.
Some tools assume permissions that do not fit neatly into hardened production environments. Sometimes the system works only after you make a compromise.
The question is not whether compromises exist. The question is whether they are explicit, documented, bounded, and reviewed.
In this stack, the root gateway decision required careful permission boundaries and heightened attention to what the agent could touch. That is the key lesson: non-standard configurations are not automatically irresponsible. Hidden non-standard configurations are dangerous.
Clinical AI deployments will face this repeatedly. The safest-looking architecture may not work. The working architecture may not be the safest. The real task is to close the gap deliberately.
Physician-developers do not need to become cybersecurity experts. But we do need to develop security instincts. Ask:
- What can this system access?
- What happens if it behaves unexpectedly?
- Where are the logs?
- Where are the secrets?
- What data are being processed?
- What data should never enter this workflow?
- Who reviews the output?
- Can the system be shut down quickly?
Those questions matter more than a vendor’s promise that the AI is “secure.”
The Model Stack: Why Failover Matters
My primary model route uses moonshotai/kimi-k2 through OpenRouter, with a failover chain that includes Claude Sonnet 4 and additional fallback capacity.
The specific model names will change over time. That is not the point.
The point is that production AI needs model flexibility.
When you build on a single model, you inherit that model’s downtime, pricing, rate limits, context behavior, latency, policy constraints, and occasional quirks. In a casual chatbot, that is tolerable. In a workflow system, it becomes a reliability problem.
A physician-builder should think in terms of model routing, not model worship.
Some tasks need stronger reasoning. Some need lower cost. Some need longer context. Some need faster latency. Some need more conservative clinical language.
A mature system routes tasks according to need.
That does not mean every physician needs a complex multi-model platform. It means that if you are building real AI workflows, do not design as if one model will always be available, affordable, and optimal. It will not.
The Rate Limit Reality
The most humbling production issue was rate limiting.
My stack encountered a practical ceiling around 30,000 tokens per minute, especially when CLI usage and Telegram-based interactions competed for the same model resources simultaneously.
This is the kind of detail that never appears in AI marketing.
The demo works because one person clicks one button. Production fails because five workflows wake up at the same time.
A devotional job runs. A Telegram request arrives. A CLI session asks for a long coding response. A summarization task begins. Suddenly the system is not limited by intelligence. It is limited by throughput.
That is a useful lesson for healthcare. A hospital AI system will not fail only because the model hallucinates. It may fail because too many users hit the same service at 8:05 AM. It may fail because a documentation workflow consumes the token budget needed for a discharge summary.
Resource governance is not optional.
For my stack, the solution was model distribution, usage pattern changes, and awareness of which workflows should not run concurrently. The larger lesson: production AI needs scheduling, routing, prioritization, and cost controls. Buying more intelligence is not a strategy.
Persistent Data Architecture
One of the most important decisions was moving persistent Hermes data away from the default home directory and into a deliberate structure:
HERMES_HOME=/opt/dataThat may seem minor. It is not.
Default paths are fine for experiments. Production workflows need intentional storage.
The stack uses:
/opt/data/skills/for the skill ecosystem/opt/data/logs/gateway.logfor production monitoring/opt/data/notes/for structured clinical, theological, and operational content
This structure made the system observable and portable. Skills could be organized, reviewed, updated, and backed up. Logs had a predictable location. Notes could be separated into meaningful hierarchies.
In healthcare language, this is the difference between a pile of scanned PDFs and a structured chart.
The data architecture determines whether future retrieval is possible.
Physicians underestimate this because we are used to EHRs hiding structure from us. But when you build your own tools, you discover quickly that file paths are not trivial. Names matter. Directories matter. Logs matter. Versioning matters.
A workflow that cannot be found later is not a workflow. It is a memory leak.
Logs Are Clinical Safety for Software
One of my most valuable production habits became watching the gateway log.
/opt/data/logs/gateway.log
That file is not glamorous. It does not have a beautiful interface. It does not give a keynote demo.
But it tells the truth.
It shows what ran, what failed, what retried, what timed out, and what needs attention.
In medicine, we understand the importance of documentation. If it is not documented, it did not happen. In software operations, logs serve the same role. They are the chart of the system.
If you are building AI tools for clinical or administrative work, logging is not optional. You need to know:
- What input triggered the workflow?
- What model was used?
- What skill was invoked?
- What output was generated?
- What failed?
- What was retried?
- What required human correction?
This is especially important for healthcare AI because safety depends on traceability. A black-box AI workflow that produces clinical text without review trails is not innovation. It is risk wearing a lab coat.
The Cost Structure
My average monthly operating cost breaks down roughly as:
- $127/month for token consumption
- $89/month for VPS infrastructure
AI operations have two kinds of costs. Direct costs: models, servers, storage, APIs. Cognitive costs: setup, debugging, reviewing, maintaining, and governing.
Most people calculate only the first.
Physician-developers must calculate both.
A tool that costs $20/month but creates an hour of cleanup every day is expensive. A tool that costs $200/month but reliably removes five hours of documentation friction may be cheap.
The right question is not “What does the AI cost?” The right question is “What workflow burden does it remove, and what new burden does it introduce?”
That second half matters. Every automation creates maintenance. If you are not willing to maintain it, do not automate it.
Clinical Data Security: The Non-Negotiable Issue
No discussion of physician AI automation is complete without PHI.
The most important rule is simple: do not casually route patient data into tools that were not designed, contracted, configured, and governed for that purpose.
In my own workflows, clinical content requires explicit routing, de-identification when appropriate, and human review before anything exits the system.
This is where many physician AI experiments go wrong. Doctors are practical. We find tools that work. We copy, paste, dictate, forward, summarize, and improvise. That instinct makes us efficient. It can also create privacy risk.
AI raises the stakes because it makes copying and transforming text feel frictionless.
The safer approach is to design lanes:
Lane 1: Non-PHI educational content. Good for blog posts, teaching summaries, generic patient education, and literature synthesis.
Lane 2: De-identified clinical scenarios. Useful for drafting templates, generic counseling language, and workflow planning.
Lane 3: Identifiable clinical documentation. Requires compliant infrastructure, appropriate agreements, access controls, auditability, and strict review.
Lane 4: Clinical decision support. Requires a higher level of validation, governance, and accountability than any other lane.
Do not confuse these lanes. A tool that is acceptable for Lane 1 may be unacceptable for Lane 3. A tool that drafts educational content should not silently become a clinical documentation pipeline.
The physician-builder’s job is to make the boundaries visible.
Why “Human in the Loop” Is Not Enough
People often say, “It is safe because there is a human in the loop.”
That phrase is incomplete.
Which human? At what step? With what authority? Reviewing what output? Against what source of truth? With how much time? Under what workload? With what documentation of the review?
A tired physician clicking approve at the end of a long day is technically a human in the loop. That does not mean the loop is safe.
For physician AI workflows, the review loop must be designed with the same seriousness as a clinical handoff.
A good loop identifies:
- The draft output
- The original source material
- The uncertain or inferred content
- The required physician verification points
- The final approved version
- The storage location
- The routing destination
The AI should make review easier, not harder. If the physician has to reverse-engineer where an output came from, the workflow is poorly designed.
The Failure Modes I Watch For
Three weeks in, I watch for several recurring failure modes.
Polished hallucination. The output sounds professional but contains invented or overconfident details.
Context bleed. The model imports assumptions from a prior task into the current task.
Workflow overreach. A drafting tool begins behaving like a decision-making tool.
Token exhaustion. A long task consumes resources needed by another workflow.
Silent failure. A cron job fails without obvious notification.
Permission creep. A useful tool gradually gains access to more than it needs.
Template rigidity. A skill follows its pattern even when the case requires nuance.
Model personality drift. Different models produce outputs with different tone, caution, and clinical conservatism.
These are manageable if you expect them. They are dangerous if you pretend the system is magic.
The Physician-Developer Advantage
Physicians are trained to manage uncertainty. That is why we can become unusually good AI supervisors.
We already know that a confident note can be wrong. We already know that incomplete data can mislead. We already know that handoffs fail. We already know that workflows break at the boundaries between people, systems, and time pressure.
Those instincts transfer directly to AI operations.
A physician-developer looks at an AI system and asks clinical questions:
- What is the indication?
- What is the risk?
- What is the failure mode?
- What is the follow-up?
- What is the source of truth?
- What happens if we are wrong?
That is the mindset healthcare AI needs. Not blind enthusiasm. Not reflexive fear. Clinical skepticism combined with builder energy.
Where I Would Go Next
If I were extending this system, I would focus on three areas.
Deeper clinical integration with appropriate compliance boundaries. EHR-compatible workflows, better ambient scribe integration, and specialty-specific documentation structures that reflect how MFM actually works.
Multi-agent workflows for complex projects. A single agent can draft. Multiple coordinated agents could research, critique, check formatting, evaluate risk, and prepare implementation plans. This must be done carefully because multi-agent systems can also multiply confusion.
Community skill sharing among physician-developers. The best skills will not come from generic prompt engineers. They will come from clinicians who understand the work.
An MFM physician should help design MFM skills. An emergency physician should help design ED handoff skills. A radiologist should help design imaging communication skills. A primary care physician should help design chronic disease follow-up skills.
That is how AI becomes clinically useful. Not by replacing expertise. By giving expertise a better interface.
A Practical Starting Path for Physicians
You do not need to begin with 94 skills. That would be the wrong lesson.
Start with one workflow.
Choose something repetitive, low-risk, and annoying.
For example:
- Turn a voice memo into a task list.
- Convert a clinical topic into patient education language.
- Draft a referral letter template.
- Summarize a meeting transcript.
- Create a GitHub issue from a feature idea.
Then ask four questions:
- What is the input?
- What is the desired output?
- What must the AI never invent?
- Where does the human review occur?
That is the beginning of an AI workflow. Not the model. The workflow.
Once that works, save it as a reusable skill. Improve it. Version it. Test it. Share it. Watch where it fails.
This is how physicians become builders. Small tools. Repeated use. Honest evaluation. Better workflows.
The Final Lesson
Running Hermes Agent in production taught me that 24/7 AI operations are not about replacing physician judgment.
They are about reclaiming physician attention.
That is the scarce resource. Not intelligence. Attention.
The modern physician is surrounded by systems that constantly fragment attention: inboxes, EHR alerts, documentation requirements, phone calls, portals, meetings, billing rules, prior authorizations, scheduling problems, software transitions, and administrative noise.
AI can add to that noise if implemented badly.
Designed well, it can remove some of it.
That is the work. Not building an AI doctor. Building an operations layer that lets doctors be doctors.
For Doctors Who Code, that is the mission.
We are not waiting for technology to rescue medicine.
We are learning enough technology to rescue pieces of our own workflow.
One skill at a time. One script at a time. One deployment at a time. One reclaimed hour at a time.
Chukwuma Onyeije, MD, FACOG is a Maternal-Fetal Medicine specialist and Medical Director at Atlanta Perinatal Associates, and the founder of CodeCraftMD and OpenMFM.org. He writes at DoctorsWhoCode.blog at the intersection of clinical medicine, software development, and AI.
Related Posts

I Gave an AI Agent 94 Skills and Let It Help Run My Clinical, Coding, and Theology Workflows
Three weeks into running Hermes Agent in production, I can say this: the real value is not the model. It is the workflow ecosystem wrapped around it. Here is what 94 specialized skills looks like in a real physician-developer stack.

Logs Before Intelligence: Why Data Discipline Must Precede AI Insight
Before you build any AI feature, you must first build the log. The principle every physician-developer needs to internalize before writing a single line of intelligence code.
I Didn't Download an App. I Described My Problem to an AI and It Built One for Me.
A Maternal-Fetal Medicine specialist describes how his personal AI health system identified low HRV, recommended breathing exercises, and prompted him to build a custom evidence-based breathing app in a single afternoon. A case study in disposable software, physician agency, and the future of personal health technology.

Maternal-Fetal Medicine Specialist