You Are Still Prompting. You Should Be Building Agents.
Prompting has a ceiling. Once you hit it, you are coordinating every step manually while the AI handles individual tasks. Here is the framework and three live workflows I use to cross that line.
Listen to this post
You Are Still Prompting. You Should Be Building Agents.
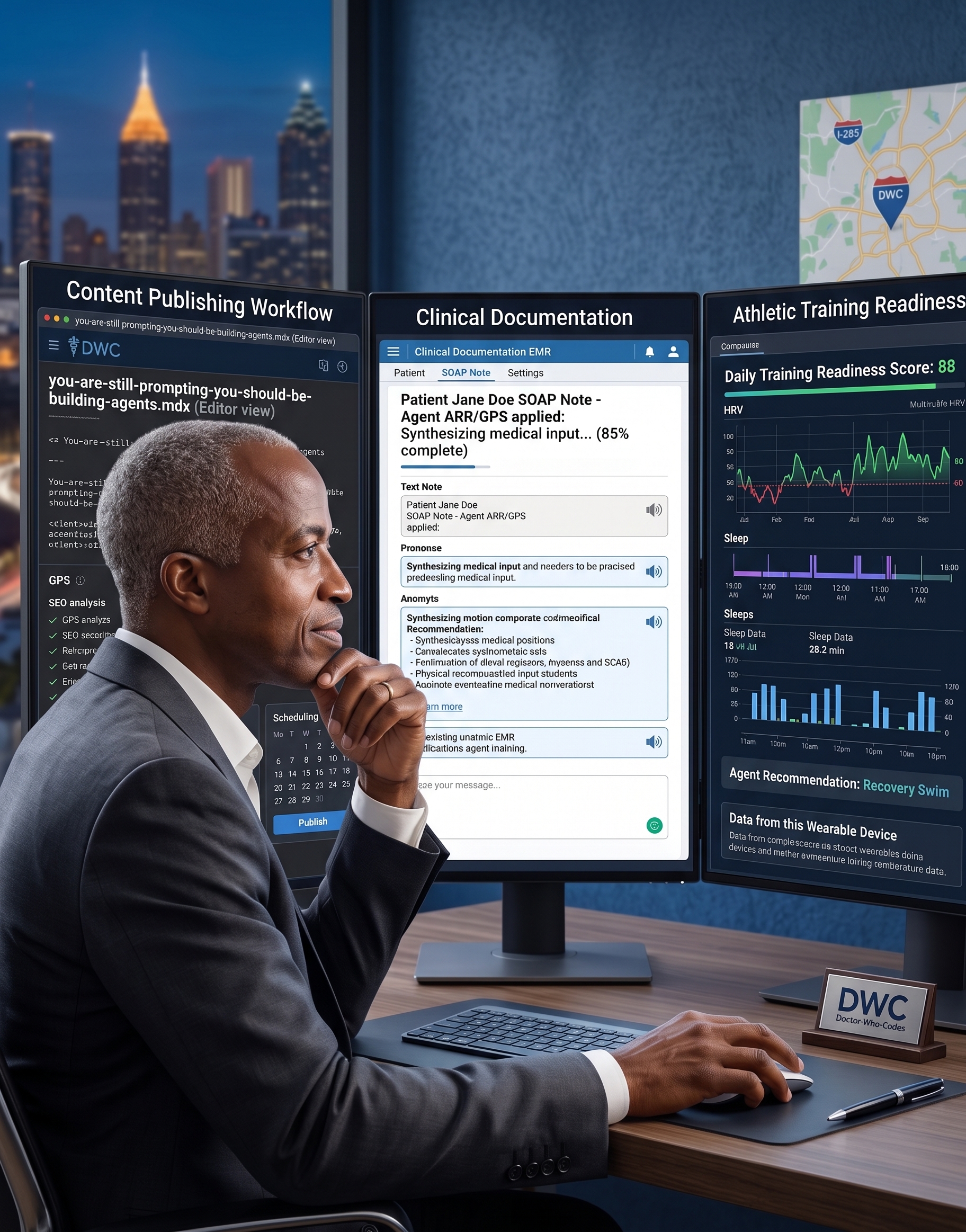
I used to sit down after a complex MFM consultation and spend twelve minutes prompting my way through the documentation.
Not twelve minutes of thinking. Twelve minutes of coordination: paste the transcript, prompt for the APSO note, read the output, copy it to AthenaHealth, realize the coding is missing, go back, prompt for codes, paste those in separately, catch a factual error in the objective, fix it manually.
The AI was doing individual tasks well. I was doing all the connecting.
That is not automation. That is assisted manual labor. There is a meaningful difference.
The Ceiling Most Physician-Developers Have Hit
Most of us learned AI the same way. We found ChatGPT or Claude, typed something in, got something back, and started figuring out how to make the output better. We learned to be specific. We learned to give context. We learned that “write a SOAP note for a 28-year-old with gestational hypertension” beats “write a note.”
Prompting is genuinely useful. It has made me faster. It has produced first drafts that would have taken an hour in twenty seconds. But prompting has a ceiling.
A prompt is a single instruction handed to a language model that produces a single output. It is stateless. The model has no memory of what it was trying to accomplish. It has no way to notice that its output was wrong and try a different approach. It has no awareness of the downstream steps that depend on what it just generated.
You are the planner. You are the error-handler. You are the quality reviewer. You are the person who decides what happens next.
This works. It just does not scale. The moment you have more than two or three steps in a workflow, you are managing a process that a well-designed system could manage for you. Every minute you spend on that coordination is a minute you are not spending on the thing only you can do.
I wrote about what this friction actually costs in Burnout Is Not From Working Too Hard. The problem is not volume. It is spending cognitive bandwidth on coordination that should not require a physician.
What an Agent Actually Is
An agent is not a smarter prompt. It is a different category of thing.
A prompt waits for you to tell it what to do. An agent takes a goal, determines the steps required to reach it, executes those steps, monitors what is happening, and adapts when something does not go according to plan. Think of the difference between a chatbot and a hired driver. The chatbot answers questions. The hired driver takes your destination, figures out the route, handles the construction delay on I-285, and gets you there without a status update every five minutes.
Inside every well-designed agent, four workers are operating.
The Analyst examines the inputs and identifies what actually matters. The Planner decides the sequence of steps required to reach the goal, selecting the right tools and approaches before execution begins. The Operator carries out the work. The Auditor reviews the output before it reaches you, checking for errors, inconsistencies, and specific failure modes.
Together, they do the coordination that you are currently doing yourself.
This architecture demands real engineering discipline. I cover what that looks like in AI Agents Do Not Replace Software Fundamentals. Agentic systems do not lower the bar for technical rigor. They raise it.
Two Checks Before You Build Anything
Not every task should be an agent. Two diagnostic tests will tell you whether a task is ready.
The ARR Test. A task needs three characteristics before it becomes an effective agent workflow.
It must be Autonomous — the system should be able to perform much of the work without constant supervision. It must be Recurring — it has to happen repeatedly, not just occasionally. It must be Reviewable — there needs to be a clear definition of what good looks like so the results can be evaluated.
If all three are yes, you have a serious automation candidate. If any one is no, you need a better-defined process before you need an agent.
The GPS Check. Before a single line of automation runs, answer three questions in writing.
Goal: Can you state the objective in one clear sentence? If it takes more than one sentence, the goal is not defined well enough to automate.
Proof: What does good actually look like, and how will you know when the agent has delivered it? “A good APSO note” is not a proof. “A note that contains all required sections, correct ICD-10 and CPT codes, no clinical data not present in the source transcript, and passes attending review in under ninety seconds” is a proof.
Steps: Can you describe every step precisely, without ambiguity? The agent will do exactly what you specify. It will not infer your intent.
The failure mode I see most often is physicians who try to automate tasks they do not fully understand themselves. They build an agent around a vague goal, get inconsistent output, blame the technology, and conclude that agents are not ready for clinical use. They are usually right about the output. They are usually wrong about the cause. The agent is not the problem. The specification is.
An agent is a mirror of your intent. It executes bad instructions as efficiently as it executes good ones. The bottleneck is never the technology. The bottleneck is the clarity of the human behind it.
Three Workflows I Am Actually Running
Here is what this looks like in practice. Three workflows across three domains of my work. Each passes the ARR test. Each was scoped with the GPS check before anything was built. Each runs the four-worker anatomy. And each one stops at a human checkpoint where the decision requires something the agent cannot provide.
Workflow One: The Post-Visit Documentation Agent
Domain: Clinical. Atlanta Perinatal Associates.
Goal: Convert every MFM encounter transcript into a complete, signed-ready APSO note in AthenaHealth within ten minutes of the visit ending.
Proof: The note contains all required sections, correct ICD-10 and CPT codes, no hallucinated clinical data, and passes attending review in under ninety seconds.
The old workflow took twelve to fifteen minutes per patient. Everything I described in the opening of this post. All of it, every patient, every day.
The agent version: the ambient scribe captures the encounter audio. The transcript is cleaned. The Analyst parses the raw clinical content, identifies the chief complaint, gestational age, ultrasound findings, and risk factors, and flags any ambiguous language for review. The Planner decides the note structure, determines whether a high-complexity modifier applies, and identifies which SMFM guideline references belong in the plan. The Operator writes the full APSO note, maps the ICD-10 and CPT codes, and pushes the draft to my AthenaHealth queue via API. The Auditor checks for missing required fields, contradictions between the subjective and objective, any medications or labs mentioned in the note that were never in the transcript, and coding accuracy.
The draft is waiting when I walk out of the room. The whole pipeline runs in ninety seconds.
My job is to review the staged draft with clinical judgment. Does the plan reflect my actual reasoning? Does the impression capture the nuance of this patient, this family, this clinical picture? I sign or I revise. I never rubber-stamp.
This is the workflow that Clinical Documentation Automation Should Remove Friction, Not Replace the Doctor is built around. The agent handles the assembly. The physician holds the clinical eye.
Workflow Two: The Idea-to-Published-Post Agent
Domain: Content. DoctorsWhoCode and Chukwuma Theology.
Goal: Transform a raw idea — a voice note, a Telegram message, an Obsidian stub — into a publish-ready MDX draft in my GitHub repository within two hours of capture.
Proof: The draft matches my established voice, has correct frontmatter with title, tags, description, and image prompt, passes my editorial checklist, and requires no structural rewriting from me. Only refinement.
The old workflow took sixty to ninety minutes per post. Voice-memo an idea in the car. Transcribe it later. Open Claude. Ask for a draft. Spend twenty minutes adjusting it to sound like me. Manually create the MDX frontmatter. Write the Facebook caption separately. Find a hero image prompt somewhere. Push the file to GitHub.
The agent version: I send a Telegram message. The Analyst reads the raw capture, classifies the content domain — is this DoctorsWhoCode, a Chukwuma Theology piece, or something in my PGIS performance framework — and surfaces related posts I have already published so the agent is not retreading ground I have already covered. The Planner selects the appropriate template: the Builder’s Seat narrative arc for DoctorsWhoCode, the expository-to-application structure for theology writing. It maps the argument before a word is written. The Operator writes the full MDX draft with frontmatter, hero image prompt, Facebook caption, and inline citations, then commits it to the correct branch with a conventional commit message. The Auditor checks voice consistency against my established style profiles, verifies all internal links, flags any unsubstantiated claims, and confirms the SEO metadata is complete.
A draft is waiting for my editorial review.
My job is to read what arrived and decide if the argument holds. Does this paragraph earn its place? Does the theological claim land where it needs to? Is my voice present, or did it drift toward something flatter? The agent is scaling my standards. It is not replacing them.
What I bring to that draft — my years of thinking about these questions, my clinical lens, my sense of what this particular audience needs to hear right now — is what the agent cannot generate. The blank page problem is solved. Everything after that is mine.
Workflow Three: The Daily Readiness and Training Agent
Domain: Athletic performance. My Performance Glycemic Intelligence System, what I call PGIS.
Goal: Generate a personalized daily training recommendation — zone, duration, and nutrition adjustments — based on the previous twenty-four hours of biomarker data.
Proof: The recommendation correctly applies my Type 1 and Type 2 Red physiological distinction, references my Stress-Glucose Index trend, aligns with my current half-marathon training block phase, and arrives before 6 AM.
The old workflow: check the Garmin app, check the CGM app, open Claude, paste in HRV and glucose data, ask for a readiness assessment, get a generic response that does not know my training block phase or my whole-food plant-based nutrition parameters.
The agent version runs overnight. The Garmin API pulls HRV, sleep quality, and training load data. The CGM pulls the nocturnal glucose trend. The Analyst ingests all of last night’s data — heart rate variability, resting HR, sleep stages, training load, nocturnal glucose baseline — and identifies the dominant readiness signal. The Planner cross-references that readiness score against my current training block phase — base, build, peak, or taper — and applies my nutrition parameters to determine the appropriate training stimulus. The Operator writes the daily readiness report: readiness tier, recommended session type and duration, target HR zones, pre-workout meal timing, and a one-line rationale. It updates the Chart.js dashboard and sends a Telegram notification. The Auditor verifies the recommendation is internally consistent — it does not prescribe hard intervals on a Red day — checks for data gaps or sensor anomalies, and flags any three-day trend that suggests a recovery week override.
I wake up to a training decision, not a spreadsheet.
The checkpoint that matters most here: the agent sees my numbers. I feel my legs. The recommendation is a starting point. I override it with body intelligence that no sensor can capture — stress from an overnight call, the early signs of a cold, disrupted sleep that the algorithm scored as acceptable but that felt nothing like rest.
That layer of judgment belongs to me. The data and the body are not the same thing.
I built the PGIS breathing module from a similar logic, described in PGIS Breathe: Disposable Software Built Around a Specific Clinical Problem. The pattern is consistent: the system captures the signal, I decide what to do with it.
The Human Checkpoint Is a Design Decision
Every workflow above has a human checkpoint. That is not a limitation of the current technology. That is the design.
The goal of an agent is not to remove the physician from the loop. The goal is to remove the physician from the parts of the loop that do not require a physician.
Formatting a note does not require a physician. Routing a file to the correct GitHub branch does not require a physician. Aggregating biomarker data and applying a scoring rubric does not require a physician.
Deciding whether the clinical impression captures the nuance of a complex patient does require a physician. Deciding whether a theological argument holds does require a physician-theologian. Deciding whether your legs feel recovered enough to run intervals despite a green HRV score requires you.
This is precisely the concern I raised in The Cognitive Surrender. Agents built without human checkpoints do not just introduce error risk. They quietly retrain you to stop exercising the judgment that makes you valuable in the first place. The checkpoint is not bureaucratic friction. It is the architecture that keeps the physician in the loop on the things that matter.
The agent handles the coordination. You handle the judgment. That is the division of labor.
What Actually Changes
When I was prompting, I was producing individual outputs faster. That was the value.
When I build agents, something different happens. I am encoding my standards into a system. The APSO note format I care about. The voice profile I have built for DoctorsWhoCode. The readiness framework I have developed inside PGIS. These are no longer things I have to reconstruct from scratch with each prompt. They are the system. They run every time without me rebuilding them.
The shift is from trading time for labor to scaling your standards and your oversight.
Your judgment is the scarce thing. The agent is the infrastructure that makes that judgment available at every iteration, without requiring you to show up for every step of the assembly.
I described what happens to the physicians who never make this shift in The Human Bottleneck. The AI is not waiting for better models. It is waiting for clearer specifications and more intentional workflows.
The physician-developer who will matter most in the next five years is not the one who prompts most efficiently. It is the one who has encoded their standards into systems that run without them in the loop, and who knows exactly when to step back in.
Build the agent. Keep the judgment.
The three workflows above are part of a broader AI operations architecture I run across clinical, content, and performance domains. See I Gave an AI Agent 94 Skills and Let It Help Run My Clinical, Coding, and Theology Workflows for the full stack.
Related Posts

AI's Next Breakthrough Is Not a Bigger Brain. It Is a Memory You Can Trust.
The AI race has been about model size for years. The real bottleneck is memory: trustworthy, auditable knowledge that persists across years, not conversations. Medicine will feel this shift first.
I Built an OpenClaw Agent to Understand What Developers Are Actually Doing (Not Because I Needed One)
Maternal-Fetal Medicine Specialist | Founder, CodeCraftMD | Atlanta Perinatal Associates

AI Agents Do Not Replace Software Fundamentals. They Expose Whether You Have Any.
For physician-builders, agentic engineering is not prompt magic. It is bounded context, vertical slices, observability, and accountability.

Maternal-Fetal Medicine Specialist